Equipment Failure Analysis in Manufacturing: How IIoT Data Turns Root Cause Investigation from Art to Science
A hydraulic press in your stamping plant fails on a Tuesday afternoon. Your most experienced maintenance technician opens the electrical cabinet, runs some tests, replaces a component, and the machine is back up in four hours. Problem solved? Not really. Without understanding why it failed, you're just waiting for it to happen again — maybe on second shift when that technician isn't there. Equipment failure analysis is the discipline of turning breakdown events into prevention strategies. And IIoT data is transforming it from tribal knowledge into repeatable science.
Why Traditional Failure Analysis Falls Short
Most manufacturing plants practice some form of failure analysis. But traditional approaches have fundamental limitations:
The Memory Problem
When a machine fails, the maintenance team fixes it and moves on. The failure details live in the technician's head, maybe in a handwritten logbook, possibly in a CMMS work order if someone remembers to enter it completely. Six months later when the same machine fails again, the institutional knowledge may have walked out the door with a retired technician.
The Data Problem
Understanding why equipment fails requires data from before the failure — the parameters that were trending toward trouble. Traditional maintenance captures what happened (bearing failed) but not the conditions leading up to it (bearing temperature rose 12°C over three weeks before failure). Without continuous parameter monitoring, you're investigating an event without context.
The Scale Problem
A mid-size manufacturing plant might have 200 machines across three locations. Tracking failure patterns, comparing failure rates across identical machines, and identifying systemic issues requires data aggregation that's impossible with manual records.
According to Deloitte's predictive maintenance research, manufacturers using data-driven failure analysis reduce unplanned downtime by 30-50% and extend equipment life by 20-40%.
The IIoT Approach to Failure Analysis
IIoT platforms change failure analysis by providing three things traditional methods lack:
1. Continuous Parameter History
Every second (or configurable interval), the IIoT platform records machine parameters: temperature, pressure, vibration, current draw, speed, cycle time. When a failure occurs, you can rewind the data to see exactly what changed leading up to the event.
This transforms investigations:
- Before IIoT: "The motor failed." → Replace motor. Cost: $5,000 + 8 hours downtime.
- After IIoT: "Motor current draw increased 22% over 11 days before failure. Root cause: misaligned coupling increased load. Replace motor ($5,000), realign coupling ($200). Also: set threshold alert at +15% current to catch this pattern on all motors."
2. Fleet-Wide Pattern Detection
When you have 50 of the same pump across 5 plants, failure analysis should span the entire fleet. IIoT platforms with fleet management capabilities can correlate failures across locations:
- Do these pumps fail more often in humid climates?
- Does the batch of pumps from 2019 have higher failure rates than the 2021 batch?
- Are certain operating conditions (high speed, high temperature) associated with earlier failure?
These insights are invisible at the single-machine or single-plant level.
3. Failure Classification and Trending
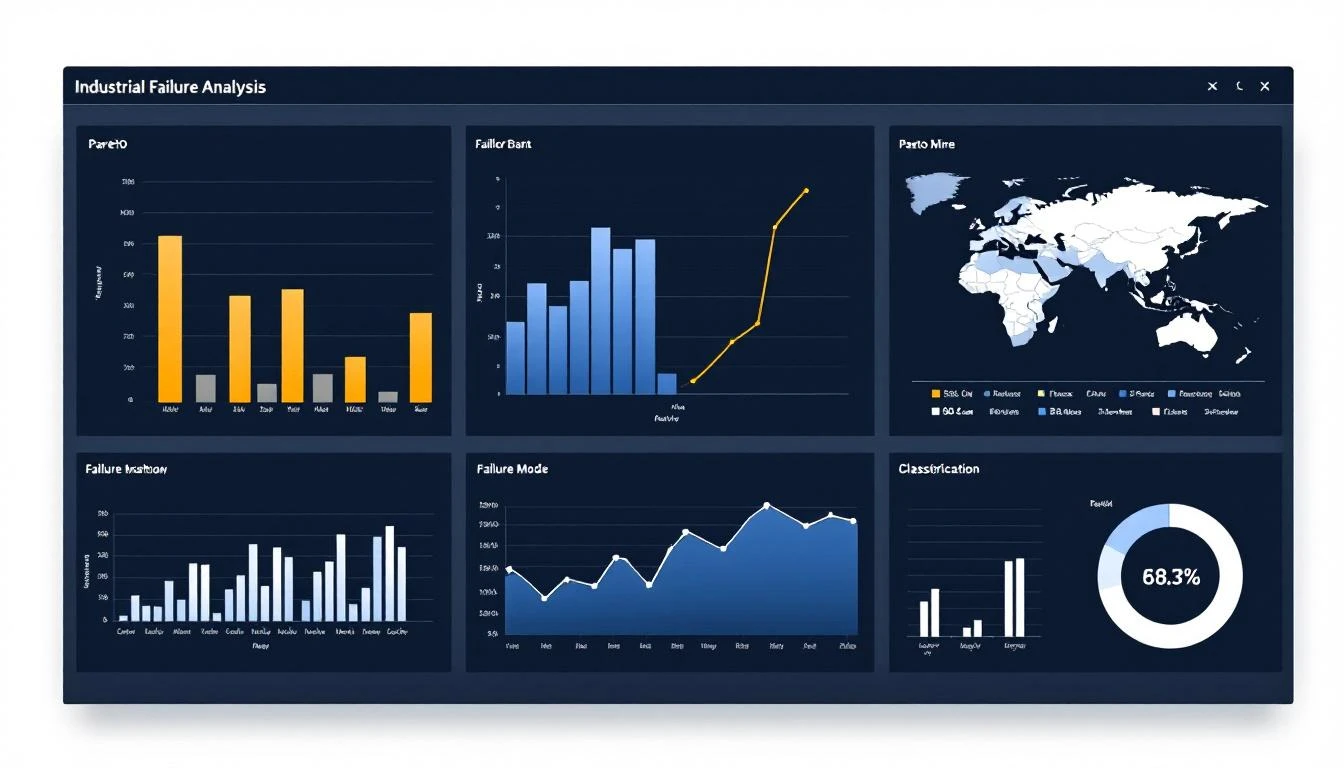
IIoT platforms categorize failures by type, machine, location, and time — enabling trend analysis:
- Failure type distribution: What percentage of failures are electrical vs. mechanical vs. process-related?
- MTBF by machine type: Which equipment types have the shortest mean time between failures?
- Failure rate trends: Are failures increasing (degrading fleet) or decreasing (maintenance improvements working)?
- Seasonal patterns: Do failures cluster in summer (heat-related) or winter (cold-start issues)?
The Failure Analysis Framework: 5 Steps
Step 1: Capture the Event
When a machine fails, the IIoT platform automatically records:
- Timestamp of the failure (when the alarm triggered)
- Machine state at the moment of failure
- Active alarms and alarm codes
- Parameter values at the time of failure
- Parameter trends leading up to the failure (hours, days, or weeks of history)
This happens without human intervention. No one needs to fill out a form or enter data into a CMMS while the machine is down and production is waiting.
Step 2: Classify the Failure
Failure classification creates the taxonomy for analysis:
- Alarm type: What kind of alarm triggered? Overtemperature, overcurrent, vibration limit, process fault?
- Alarm status: First occurrence, recurring, or escalating?
- Failure category: Mechanical, electrical, process, operator, material-related?
- Severity: Production-stopping, performance-degrading, or cosmetic?
IIoT platforms with configurable alarm types and downtime reason codes enable consistent classification across all machines and all plants.
Step 3: Investigate Root Cause
With the failure captured and classified, investigation uses the IIoT data:
Short-term analysis (what happened):
- Review parameter trends in the 24 hours before failure
- Identify the first parameter that deviated from normal
- Check if any threshold alerts were triggered (and if they were responded to)
- Review operator actions before the failure
Long-term analysis (why it keeps happening):
- Compare this failure to previous failures on the same machine
- Compare to failures on identical machines at other locations
- Check maintenance history — was a scheduled PM missed?
- Review spare parts history — was a non-OEM part installed last time?
Step 4: Implement Corrective Action
Root cause analysis is only valuable if it leads to action:
- Immediate fix: Repair the machine (obviously)
- Detection improvement: Set threshold alerts to catch the precursor condition earlier
- Prevention: Adjust PM schedule, replace at-risk components proactively, modify operating parameters
- Fleet-wide action: Apply learnings to all identical machines across all plants
Step 5: Validate the Fix
After implementing corrective action, IIoT data validates whether the fix actually worked:
- Monitor the repaired machine for parameter stability
- Track MTBF — did the time between failures increase?
- Watch fleet-wide metrics — did the failure pattern stop appearing on other machines?
This closed-loop approach — capture → classify → investigate → correct → validate — turns each failure into a permanent improvement. Without IIoT data, the loop breaks at steps 1, 3, and 5.
Fleet-Level Failure Analysis
The most powerful application of IIoT failure analysis operates at the fleet level. MachineCDN's fleet management module includes failure analysis dashboards that aggregate failure data across all locations, providing:
Spare Parts Consumption Analysis
Failure analysis isn't just about the failure event — it's about the parts you consume fixing failures. Fleet-level spare parts tracking reveals:
- Which parts are consumed most frequently (indicating a chronic failure mode)
- Which machines consume the most spare parts (candidates for overhaul or replacement)
- Which locations have the best and worst parts consumption rates
When your Ohio plant uses three times as many bearings per machine-year as your Texas plant, the failure analysis points to either operating conditions, maintenance practices, or bearing quality differences between locations.
Machine Type Failure Comparison
Bar charts comparing failure rates by machine type across the fleet answer strategic questions:
- Should we keep buying Brand X extruders, or does Brand Y have better reliability?
- Are our 2018-vintage machines approaching end-of-life faster than expected?
- Which machine category needs the most maintenance investment?
Company-Level Aggregation
For organizations managing machines across multiple business units or subsidiary companies, failure analysis can aggregate by organizational entity — enabling performance benchmarking between divisions.
Connecting Failure Analysis to Predictive Maintenance
Failure analysis data becomes the training set for predictive maintenance. Every failure event includes:
- The parameters that preceded the failure (features)
- The type of failure that occurred (label)
- The timeline from deviation to failure (prediction window)
After accumulating enough failure events, the IIoT platform can:
- Recognize similar patterns on other machines before they fail
- Alert maintenance with "this machine is showing early signs of bearing degradation" instead of "bearing failed"
- Predict remaining useful life based on the rate of parameter deviation
- Prioritize maintenance by ranking machines by failure probability
This is the transition from reactive ("fix when broken") to predictive ("fix before it breaks") — and failure analysis data is the foundation that makes it possible.
Common Failure Analysis Mistakes
Stopping at the Symptom
"The motor overheated" is a symptom, not a root cause. The IIoT data might reveal that motor temperature increased because current draw increased, which happened because the coupling was misaligned, which happened because the foundation bolts loosened due to vibration from an adjacent machine. Stopping at "motor overheated" means you'll replace the motor, and it'll overheat again in 6 months.
Ignoring Low-Severity Failures
Not every failure stops production. Performance degradation — slower cycle times, increased scrap, higher energy consumption — represents failure in slow motion. IIoT trend analysis catches these gradual declines that operators often dismiss as "normal aging."
Not Sharing Across Plants
When Plant A solves a failure mode but doesn't tell Plant B, Plant B discovers (and suffers from) the same failure independently. Fleet-level failure analysis and shared corrective actions prevent redundant problem-solving.
Treating Every Failure as Unique
Many failures are repeats of known patterns. The IIoT platform's historical data should be searched before launching a new investigation. "We've seen this before on Machine 7 in 2024 — here's what caused it and what we did" saves hours of investigation.
Getting Started with Data-Driven Failure Analysis
For plants beginning their IIoT failure analysis journey:
- Start capturing alarm data systematically. Configure alarm types and severities for all monitored machines.
- Define your downtime reason codes. Create a consistent taxonomy across all machines and locations.
- Review the first 90 days of data. Look for patterns: which machines fail most, what types of failures dominate, are there time-based patterns?
- Implement threshold alerts for the top 3 failure precursors you identified.
- Track MTBF by machine and watch for improvements as you act on the data.
Ready to transform your failure analysis? Book a demo with MachineCDN and see fleet-level failure analysis, spare parts tracking, and predictive maintenance data working together — across all your plants.